NeurIPS 2025 Highlights
NeurIPS 2025 Highlights: Audio Understanding and Generation
Table of Contents
- Large Audio Language Models and Benchmark
- Spatial Audio
- Audio Generation
- Audio Guided Generation
1. Large Audio Language Models and Benchmark
AVCD: Mitigating Hallucinations in Audio-Visual Large Language Models through Contrastive Decoding
Paper: [OpenReview] 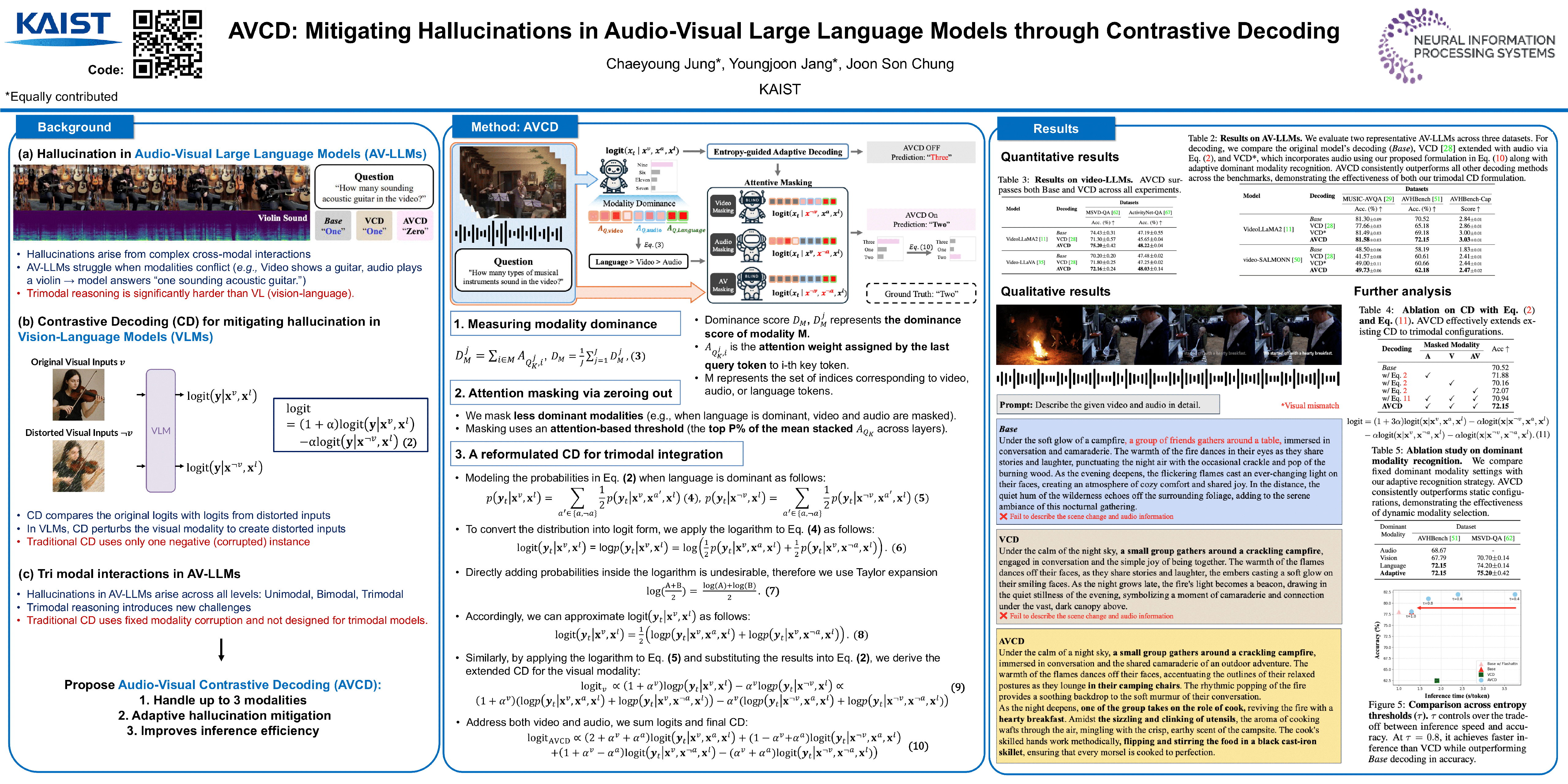 This paper proposes Audio-Visual Contrastive Decoding (AVCD), a training-free, inference-time method to reduce hallucinations in audio-visual LLMs by balancing how much the model relies on audio, video, and language.
This paper proposes Audio-Visual Contrastive Decoding (AVCD), a training-free, inference-time method to reduce hallucinations in audio-visual LLMs by balancing how much the model relies on audio, video, and language.
The key idea is to detect which modality dominates a prediction using the model’s attention distribution, then selectively mask the less dominant modalities to generate biased logits. These are contrasted with the original logits so the model is discouraged from hallucinating based on a single modality or misaligned audio-visual cues. Unlike prior contrastive decoding methods that corrupt a fixed modality, AVCD is dynamic and trimodal-aware. To keep inference efficient, they add entropy-guided adaptive decoding, skipping contrastive steps when the model is already confident.
Experiments on AVHBench, MUSIC-AVQA, and video QA benchmarks show consistent gains on VideoLLaMA2 and video-SALMONN, demonstrating that AVCD is a plug-and-play way to improve AV-LLM reliability without retraining.
MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix
Paper: [arxiv] 
Core idea
MMAR introduces the first benchmark explicitly designed to evaluate deep reasoning over audio, rather than surface-level audio understanding. It consists of 1,000 human-curated, multi-step audio QA tasks spanning speech, sound, music, and real-world mixtures, organized into a four-layer reasoning hierarchy (Signal, Perception, Semantic, Cultural) with expert-annotated Chain-of-Thought (CoT) rationales. The benchmark reveals that even strong audio-language models struggle to reason beyond shallow semantic cues.
Mellow: a small audio language model for reasoning
Paper: [OpenReview] 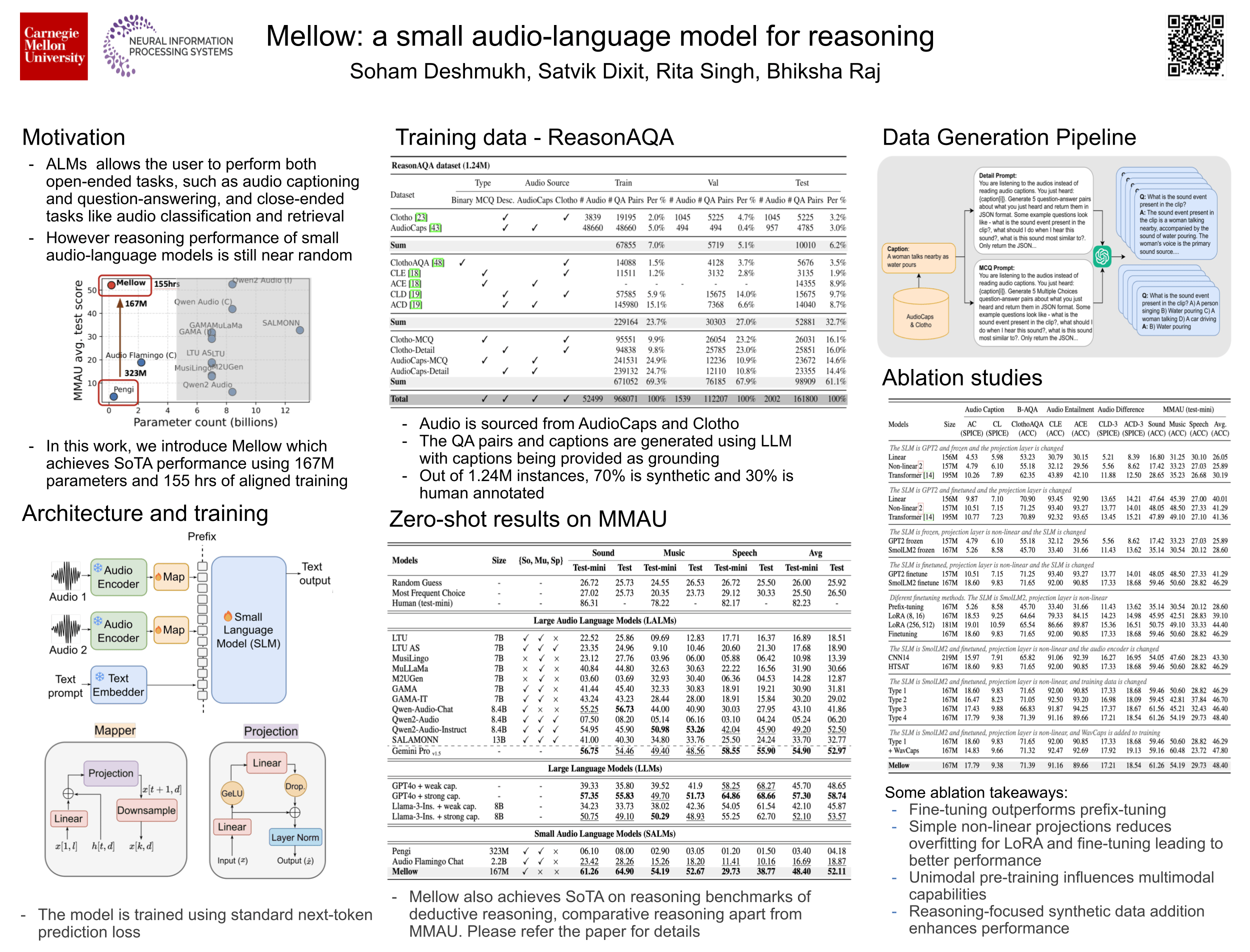
Mellow shows that strong audio reasoning does not require a large model. The paper presents a very small audio–language model (~167M parameters) that can listen to audio and answer reasoning questions, such as comparing sounds or judging whether a statement is true given the audio. Instead of scaling model size or data, the authors focus on training with reasoning-oriented audio QA. They also introduce ReasonAQA, a new dataset built from AudioCaps and Clotho, where most questions are synthetically generated to explicitly target audio-grounded reasoning rather than simple recognition. Despite its small size, Mellow reaches similar reasoning performance to much larger models (e.g., 8B-scale models) on MMAU. The key takeaway is that reasoning ability can be trained, rather than emerging only from scale. This is especially relevant for on-device or low-latency audio systems, where model size and efficiency matter, even though the model remains weak on speech and mainly focuses on sound and music.
Watch and Listen: Understanding Audio-Visual-Speech Moments with Multimodal LLM
Paper: [OpenReview] 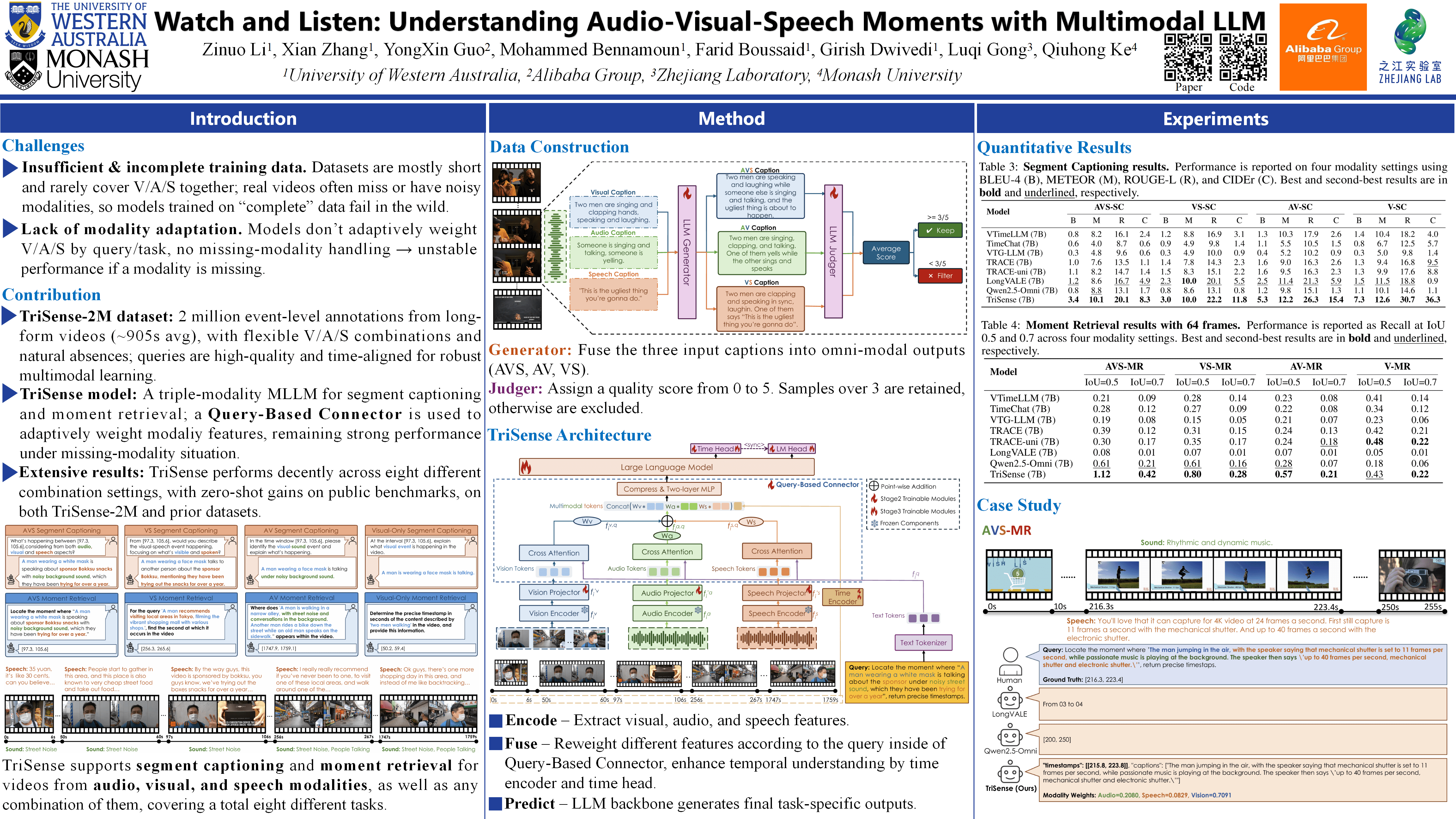
TriSense makes several contributions that are directly useful for practical systems. First, the query-based modality weighting is a concrete and reusable idea: instead of always fusing vision, audio, and speech equally, the model learns to emphasize the modalities that actually matter for a given query, which is highly relevant for real-world media where audio may be noisy, missing, or more important than visuals. Second, TriSense-2M is valuable not just for scale, but for how it is built: long videos, explicit audio–visual–speech alignment, and systematic coverage of modality dropout, which better matches real production content than short, clean clips. Third, the task setup—moment retrieval and segment captioning under different modality combinations—is a realistic evaluation framework that can be reused to test multimodal systems beyond vision-only baselines. Overall, the paper contributes usable design patterns (adaptive fusion), usable data construction strategies (LLM-based multimodal annotation with quality control), and a benchmark setting that aligns well with real audio-visual pipelines rather than idealized lab conditions.
Jailbreak-AudioBench: In-Depth Evaluation and Analysis of Jailbreak Threats for Large Audio Language Models
Paper: [OpenReview], [Page] 
The paper shows that safety failures in audio language models do not come from changing what is said, but from changing how it is said. Audio naturally carries expressive cues that text does not, such as emphasis, speaking rate, intonation, emotion, and background noise. In end-to-end audio language models, these cues are directly encoded into joint hidden representations rather than being filtered through a stable, trusted text bottleneck. As a result, safety alignment—largely trained on semantic intent—can become unstable when non-semantic style signals dominate the model’s internal states. The authors find that all models can initially detect audio modifications, but only stronger models are able to normalize these effects back into purely semantic representations in later layers. Weaker or mid-tier models retain these distortions throughout the network, making safety behavior increasingly probabilistic. This issue becomes more severe when multiple audio style changes are combined, as their effects accumulate and overwhelm the model’s ability to separate meaning from delivery. Overall, the paper highlights that audio introduces a real and under-evaluated safety surface, where safety mechanisms designed for text alone are no longer sufficient.
DAVE: Diagnostic benchmark for Audio Visual Evaluation

This paper introduces DAVE, a benchmark meant to test whether audio-visual models truly use both audio and vision. Its main contribution is not model design, but evaluation clarity. DAVE removes the strong visual bias present in existing benchmarks by ensuring that each question requires both modalities. It also breaks audio-visual understanding into a small set of diagnostic tasks—synchronization, absence detection, and sound discrimination—so failures can be traced to specific weaknesses instead of being hidden by a single accuracy score. By evaluating current models under this setup, the paper shows that most systems can recognize actions visually but struggle to align sounds with actions in time or reason about missing audio. Overall, DAVE provides a simple but effective diagnostic tool for exposing where multimodal reasoning actually breaks, rather than how well models exploit shortcuts.
Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models
Page: [page] Paper: [OpenReview]
Audio Flamingo 3 (AF3) presents a fully open large audio-language model that aims to unify reasoning across speech, sound, and music within a single system. The core contribution is not just higher benchmark scores, but showing that strong audio reasoning requires deliberate data design and training strategy rather than scaling alone. AF3 introduces a unified audio encoder (AF-Whisper) instead of separate encoders per audio type, and trains the model with a curriculum that gradually increases reasoning difficulty and audio length, reaching up to 10 minutes. The model also supports optional, on-demand chain-of-thought style reasoning, multi-turn multi-audio dialogue, and voice-to-voice interaction. Crucially, the authors release the full stack—model weights, training recipes, and several large datasets—making AF3 one of the most transparent and reproducible audio LLMs to date. Overall, the paper demonstrates that audio reasoning, long-context understanding, and interactive audio dialogue can be achieved in a single open model, provided that data curation and training objectives are explicitly aligned with reasoning rather than recognition.
Main usable contributions are:
- a unified speech–sound–music encoder,
- large-scale reasoning-focused audio QA datasets,
ThinkSound: Chain-of-Thought Reasoning in Multimodal LLMs for Audio Generation and Editing

ThinkSound proposes a reasoning-driven framework for video-to-audio generation and editing, arguing that high-quality sound design requires explicit reasoning rather than a single end-to-end mapping from video to audio. Inspired by how human sound designers work, the system decomposes audio creation into a step-by-step process guided by chain-of-thought (CoT) reasoning generated by a multimodal LLM. The pipeline consists of three stages—foundational foley generation, object-centric refinement via user clicks, and instruction-based audio editing—all supported by a single unified audio foundation model. At each stage, the LLM produces structured reasoning that explains what sounds should exist, when they should occur, and how they relate to visual events, and this reasoning directly conditions audio synthesis.
A key contribution is AudioCoT, a large dataset with explicit audio-specific reasoning annotations that link visual content, textual descriptions, and sound synthesis decisions. Experiments show that CoT guidance consistently improves audio quality, temporal alignment, and controllability, and removing CoT leads to clear degradation across both objective and human-rated metrics. Overall, the paper’s main insight is that reasoning should be treated as a first-class component in audio generation: explicitly modeling temporal and causal structure enables more faithful, editable, and user-controllable audio than black-box video-to-audio models.
2. Spatial Audio
Attention on the Sphere
(NVIDIA)
Repo: [torch-harmonics] Paper: [arXiv]
Attention on the Sphere shows how to apply Transformer attention directly on spherical data instead of flattening it into a 2D image. This is important for spatial audio, because many things we work with—such as sound direction, HRTFs, ambisonics, and immersive sound scenes—naturally live on a sphere around the listener. The method helps models treat all directions equally and behave consistently when the listener or scene rotates, which is hard to guarantee with standard 2D approaches. For Dolby, this points to a clean way to build future spatial-audio models that are more stable, direction-aware, and better aligned with how sound is perceived in 3D space.
DeepASA: An Object-Oriented Multi-Purpose Network for Auditory Scene Analysis
The paper proposes DeepASA, a single multi-task “auditory scene analysis” model that tries to treat each sound source as an object and then solve multiple downstream tasks consistently for that same object: multichannel (MIMO) source separation + dereverberation + sound event detection (SED) + audio classification + direction-of-arrival estimation (DoAE).
MRSAudio: A Large-Scale Multimodal Recorded Spatial Audio Dataset with Refined Annotations
MRSAudio introduces a large-scale, real-world multimodal dataset designed specifically for spatial audio research, addressing a key limitation of existing audio–visual datasets that rely mostly on monaural audio. The dataset contains 484 hours of recorded data with synchronized binaural and ambisonic audio, video, 3D source trajectories, and fine-grained semantic annotations, covering four complementary scenarios: daily life sounds, speech, singing, and music. Unlike simulated or weakly annotated corpora, MRSAudio is fully recorded and carefully aligned, enabling models to learn physically grounded spatial cues such as direction, distance, and motion. The authors also establish standardized benchmarks across five spatial tasks—audio spatialization, spatial TTS, spatial singing synthesis, spatial music generation, and sound event localization—and show that existing methods benefit significantly from the dataset’s spatial richness and annotation quality. Overall, the main contribution is not a new model, but a comprehensive, reusable foundation for studying spatial audio understanding and generation under realistic multimodal conditions, making MRSAudio a strong reference dataset for immersive media and spatial audio research.
SAVVY: Spatial Awareness via Audio-Visual LLMs through Seeing and Hearing
This paper introduces SAVVY-Bench, where the data includes multi-track (multi-channel) spatial audio, but the audio is not used for semantic understanding. Instead, it is treated purely as a spatial cue (direction and distance) to localize sound sources over time. The model then uses this localization as structured input to help an AV-LLM answer 3D spatial questions (egocentric/allocentric), rather than learning spatial reasoning end-to-end.
Empirically, standard AV-LLMs (even strong ones like Gemini-2.5-Pro) struggle badly on allocentric and out-of-view cases because they rely on mono audio and weak temporal grounding. Plugging in SAVVY yields large gains, reaching 58.0% overall accuracy vs. 50.9% for Gemini-2.5-Pro, with especially strong improvements on allocentric direction and distance—the hardest settings. The takeaway is clear: spatial audio + explicit geometry + modular reasoning beats end-to-end “reasoning in text” for 3D spatial understanding in dynamic scenes.
3. Audio / Music Generation
Audio Super-Resolution with Latent Bridge Models
Paper: [OpenReview] Demo: [Page]
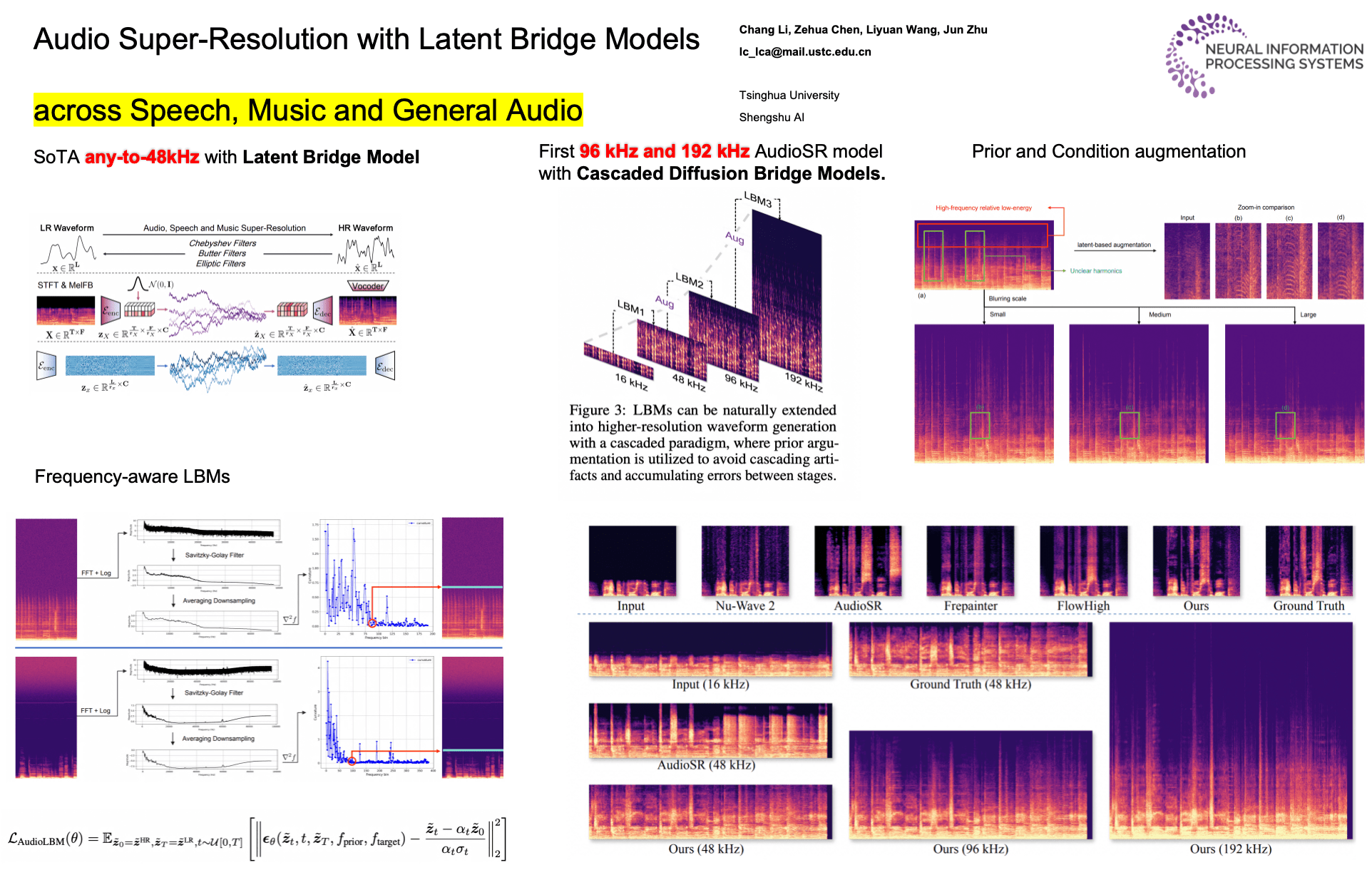
The main significance of this paper is that most current generative audio models operate at 16 or 24 kHz and focus primarily on semantic correctness (e.g., intelligible speech or recognizable events), rather than on high-fidelity listening quality. In contrast, Dolby’s priorities center on perceptual audio quality and immersive listening experience, where high sample rates and accurate high-frequency content matter. This work shows that generating or reconstructing high-sample-rate audio (48 kHz to 192kHz) is both feasible and valuable, and highlights an important gap between today’s mainstream generative audio research and the requirements of premium audio production and playback pipelines.
ZeroSep: Separate Anything in Audio with Zero Training
Paper: [OpenReview]
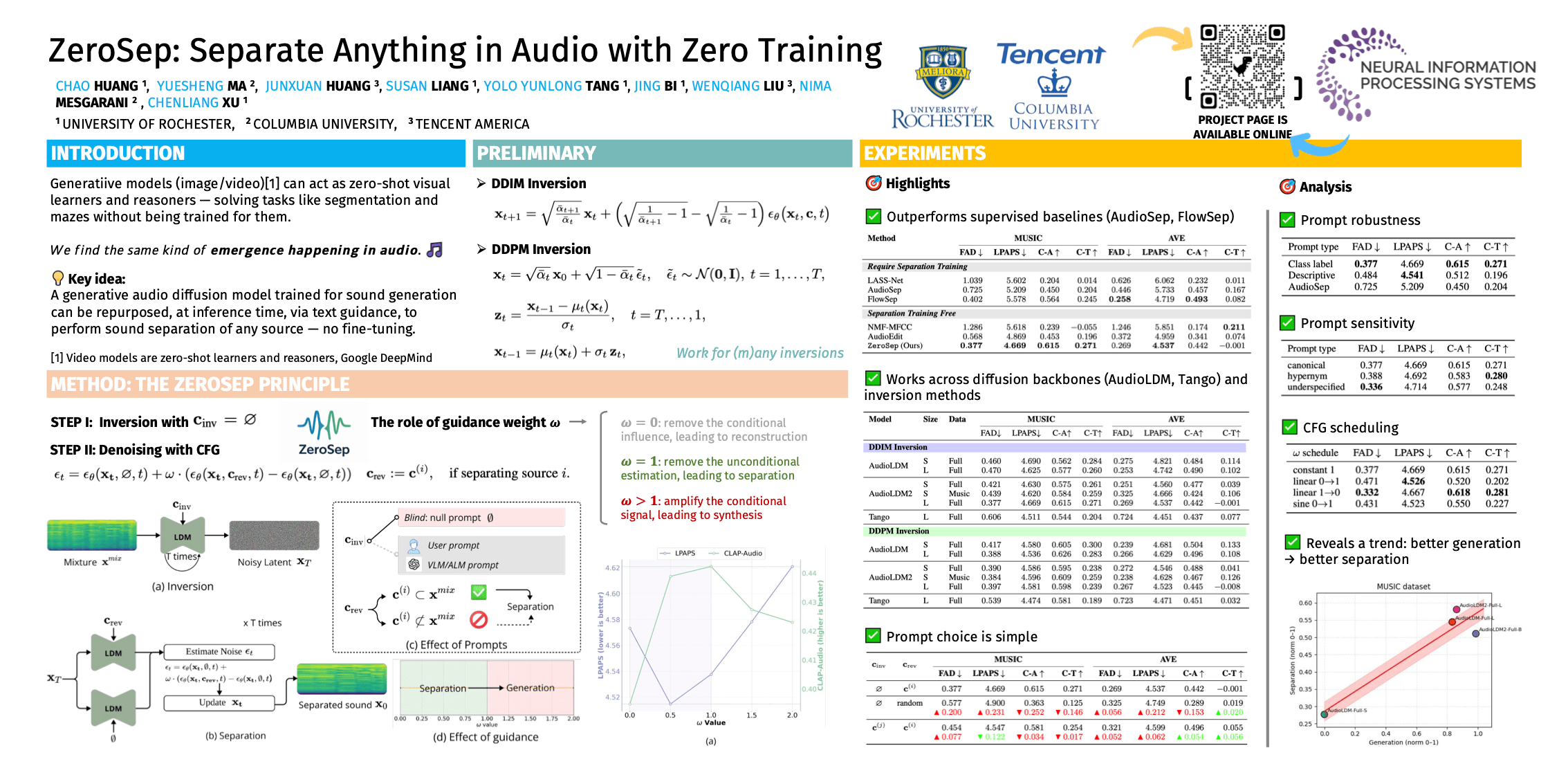
This paper proposes ZeroSep, a method for audio source separation without any separation training. Instead of training a model to separate sounds, the authors reuse a pre-trained text-to-audio diffusion model and turn it into a separator at inference time. The key idea is to first invert a mixed audio signal into the diffusion model’s latent space, then run the denoising process again while conditioning on a text prompt describing the target sound (for example, “dog barking”). By carefully controlling classifier-free guidance, the model reconstructs only the audio components consistent with that text prompt, effectively isolating the source. This purely generative procedure matches or even outperforms supervised separation systems on standard benchmarks. The paper shows that strong separation emerges because diffusion models implicitly learn disentangled representations of multiple sound sources during large-scale generative training. Overall, ZeroSep demonstrates that modern audio diffusion models can act as general, open-set separators, turning text-guided generation into a powerful, training-free alternative to traditional supervised source separation.
StylePitcher: Generating Style-Following and Expressive Pitch Curves for Versatile Singing Tasks
(NeurIPS 2025 Workshop on AI for Music: Where Creativity Meets Computation) Paper: [arXiv] Demo: [page] StylePitcher proposes a general-purpose pitch curve generator that captures singer-specific expressive style (e.g., vibrato, slides, pitch bends) while staying aligned with the intended melody. Instead of treating pitch as singer-agnostic or building task-specific pitch modules, the paper formulates pitch generation as a masked infilling problem and uses a rectified flow (flow matching) Transformer to regenerate missing F0 segments conditioned on musical scores and surrounding pitch context. This enables implicit style learning from reference audio without singer labels and allows the same model to be used plug-and-play across tasks. Once trained, StylePitcher adapts to automatic pitch correction, zero-shot singing voice synthesis with style transfer, and style-informed singing voice conversion without retraining. Experiments on large multi-speaker singing datasets show that it improves style similarity and perceived audio quality, while maintaining pitch accuracy comparable to or better than task-specific baselines.
Unifying Symbolic Music Arrangement: Track-Aware
Reconstruction and Structured Tokenization
Paper: [OpenReview], [Page] Code: [GitHub] 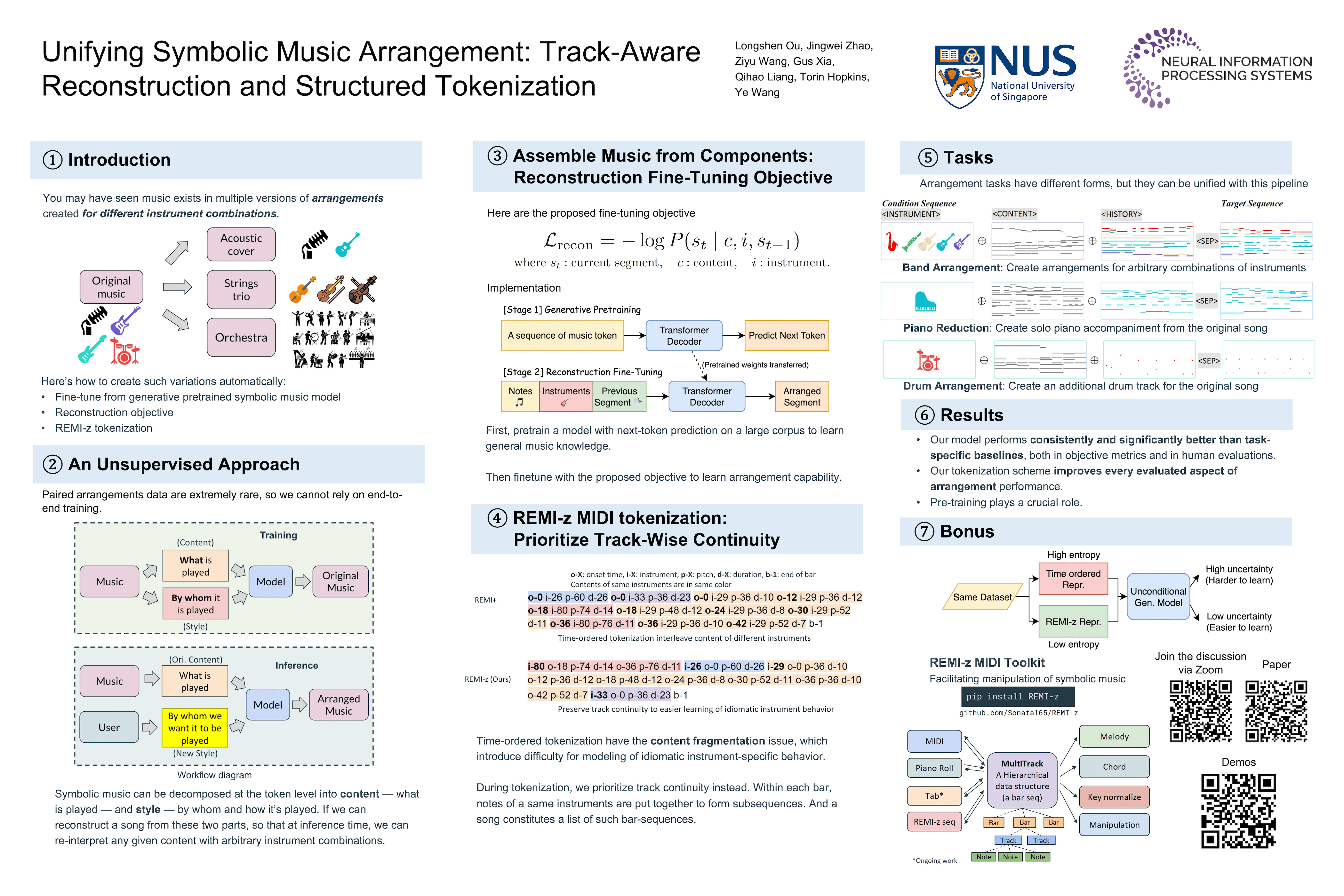 This paper proposes a unified method for automatic music arrangement using symbolic MIDI data. Instead of building separate models for different tasks (such as band arrangement, piano reduction, or drum arrangement), the authors show that all of them can be handled by one pre-trained symbolic music model through a shared reconstruction objective. The key idea is to explicitly separate musical content (notes and timing) from instrumentation (which instrument plays what), and train the model to reconstruct target tracks from these components without requiring parallel arrangement datasets. To make this work effectively, the paper introduces REMI-z, a new MIDI tokenization scheme that preserves track-wise continuity and improves instrument control. Experiments show that this approach outperforms task-specific baselines across multiple arrangement scenarios, demonstrating that careful objective design and tokenization are enough to unlock flexible, general-purpose symbolic music arrangement.
This paper proposes a unified method for automatic music arrangement using symbolic MIDI data. Instead of building separate models for different tasks (such as band arrangement, piano reduction, or drum arrangement), the authors show that all of them can be handled by one pre-trained symbolic music model through a shared reconstruction objective. The key idea is to explicitly separate musical content (notes and timing) from instrumentation (which instrument plays what), and train the model to reconstruct target tracks from these components without requiring parallel arrangement datasets. To make this work effectively, the paper introduces REMI-z, a new MIDI tokenization scheme that preserves track-wise continuity and improves instrument control. Experiments show that this approach outperforms task-specific baselines across multiple arrangement scenarios, demonstrating that careful objective design and tokenization are enough to unlock flexible, general-purpose symbolic music arrangement.
4. Audio Guided Generation
MOSPA: Human Motion Generation Driven by Spatial Audio
Paper: [arXiv]
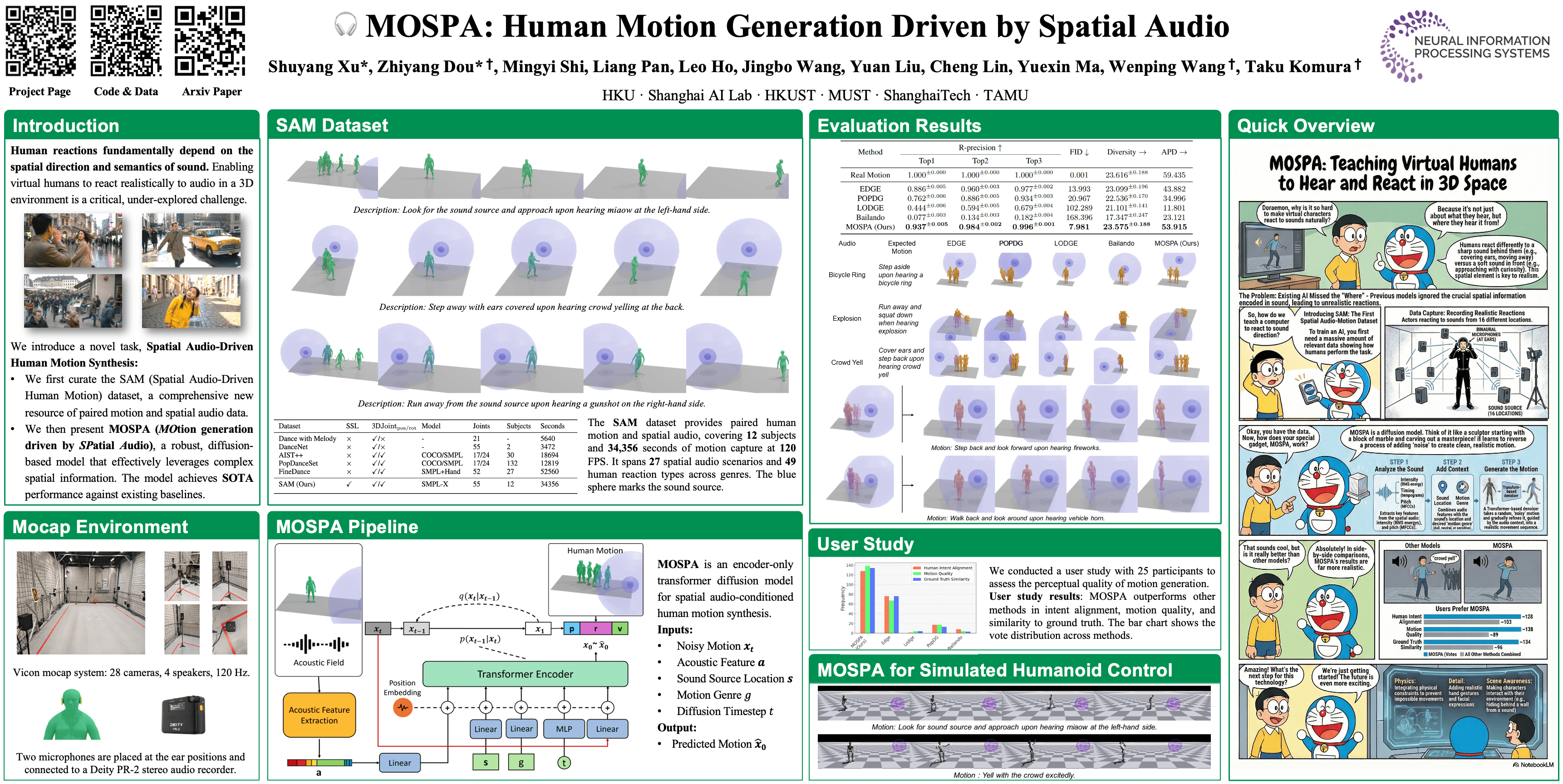
MOSPA studies human motion generation driven by spatial audio, focusing on how people naturally react to the location and type of a sound source (e.g., turning toward a sound, stepping away, covering ears). While the paper uses spatial audio, audio mainly acts as a simple signal and direction cue, rather than a rich acoustic representation—the model relies on basic features like energy, timing, and source location instead of detailed sound content or rendering quality. As a result, the work is more about behavior and motion response than audio understanding itself. For Dolby, this is relevant mainly as an application example showing how spatial audio cues can drive downstream agents or avatars, rather than as a contribution to spatial audio modeling or rendering.
VASA-3D: Lifelike Audio-Driven Gaussian Head Avatars from a Single Image
This paper proposes VASA-3D, a method that turns one single portrait image into a real, animatable 3D head avatar that can be driven by any speech audio to generate free-viewpoint talking-head videos in real time. The key trick is that they reuse the strong “motion latent” learned by VASA-1 (a very realistic 2D talking-head generator trained on many subjects) and translate that motion representation into 3D: they bind a 3D Gaussian splatting head to a FLAME model for basic geometry and pose, then add an extra VASA-latent-conditioned residual deformation field to capture subtle facial micro-motions and expression details that FLAME alone cannot represent well. Since they only have one input image, they create training supervision by using VASA-1 to synthesize many frames (different expressions/poses) from that image, then optimize the 3D Gaussian avatar against those frames with losses designed to handle synthetic artifacts and limited pose coverage; they also add an SDS-style regularization to improve side views. The result is high-quality, lip-synced, expressive 3D heads that render at 512×512 up to ~75 FPS on a consumer GPU, while supporting extra controls like emotion offsets.